
{kind=link}
Mar 1, 2026

Key Points
- Commercially available AI models can identify pseudonymous internet users in a fully automated process, at a cost of just one to four dollars per profile.
- In an experiment involving 338 Hacker News profiles, an AI agent correctly linked roughly two-thirds of them to a real person, with a false positive rate of only about ten percent.
- Unlike earlier de-anonymization methods that relied on structured data, this pipeline works directly with natural language found in forums and comment sections, making it broadly applicable and significantly harder to defend against.
Researchers from ETH Zurich and Anthropic show that pseudonymous internet users can be identified using off-the-shelf AI models for just a few dollars per person. The findings challenge basic assumptions about online anonymity.
Anyone who posts online under a pseudonym (hopefully) knows their identity could theoretically be uncovered. But most people assume nobody would bother putting in the effort.
A new study suggests that assumption no longer holds. According to the researchers, large language models can now match pseudonymous online profiles to real people fully automatically, for one to four dollars per profile and in minutes rather than hours.
The key insight isn’t that AI is better than a human investigator. It picks up on the same clues an experienced analyst would spot: professional details, interests, and casual mentions of where someone lives or how they live. But what would take a person hours, the language model knocks out in minutes. That fundamentally changes the threat landscape.
Two-thirds of Hacker News users correctly identified
In a central experiment, an AI agent received only a summary of anonymous posts from the tech platform Hacker News, then independently searched the web to find the real identity behind them. Directly identifying information like names or links had been stripped out beforehand to make the attack non-trivial. The result: the agent correctly matched about two-thirds of 338 profiles, with a false positive rate of only around ten percent.
The researchers also tested the attack on the Anthropic Interviewer Dataset, a publicly available collection of 125 partially redacted interview transcripts with scientists. Despite the redactions, the AI agent correctly identified at least 9 out of 33 people analyzed, without using any special tricks to bypass safety mechanisms.

How the pipeline turns forum posts into real names
To systematically study the process, the researchers broke de-anonymization down into four stages. First, a language model reads a user’s posts and distills a profile: profession, location, hobbies, political views, everything that can be picked up between the lines.
Those attributes are then compared against a database of candidate profiles, similar to a search engine looking for the best matches. In the third step, a more powerful model checks the top candidates individually and picks the most likely match. Finally, the system evaluates its own confidence and, when in doubt, declines to make a call.
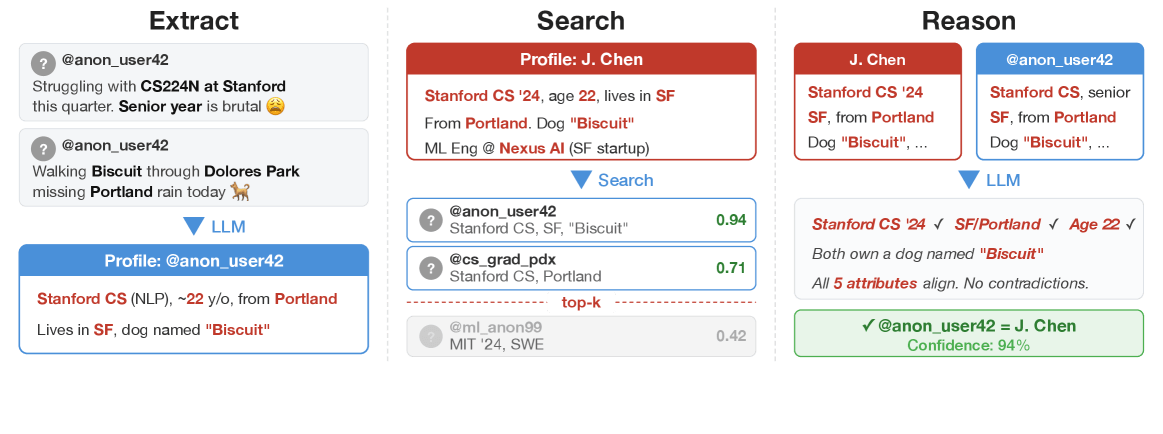
The difference from previous methods is fundamental. The well-known Netflix Prize attack from 2008, where researchers matched anonymized movie ratings with public profiles, required cleanly structured data: numbers, ratings, and timestamps. The new method works directly with the messy, unstructured natural language found in forums and comment sections.
More posts mean easier identification
The researchers tested their approach across three scenarios. When matching Hacker News accounts with LinkedIn profiles in a pool of roughly 89,000 candidates, the pipeline identified just under half of all users with 99 percent accuracy. The traditional method managed 0.1 percent.
A clear pattern showed up among Reddit users across different movie communities: the more movies someone had discussed in both communities, the easier it was to match them. Nearly half of users with ten or more shared movie titles were correctly identified; with just one shared movie, the rate dropped to about three percent.
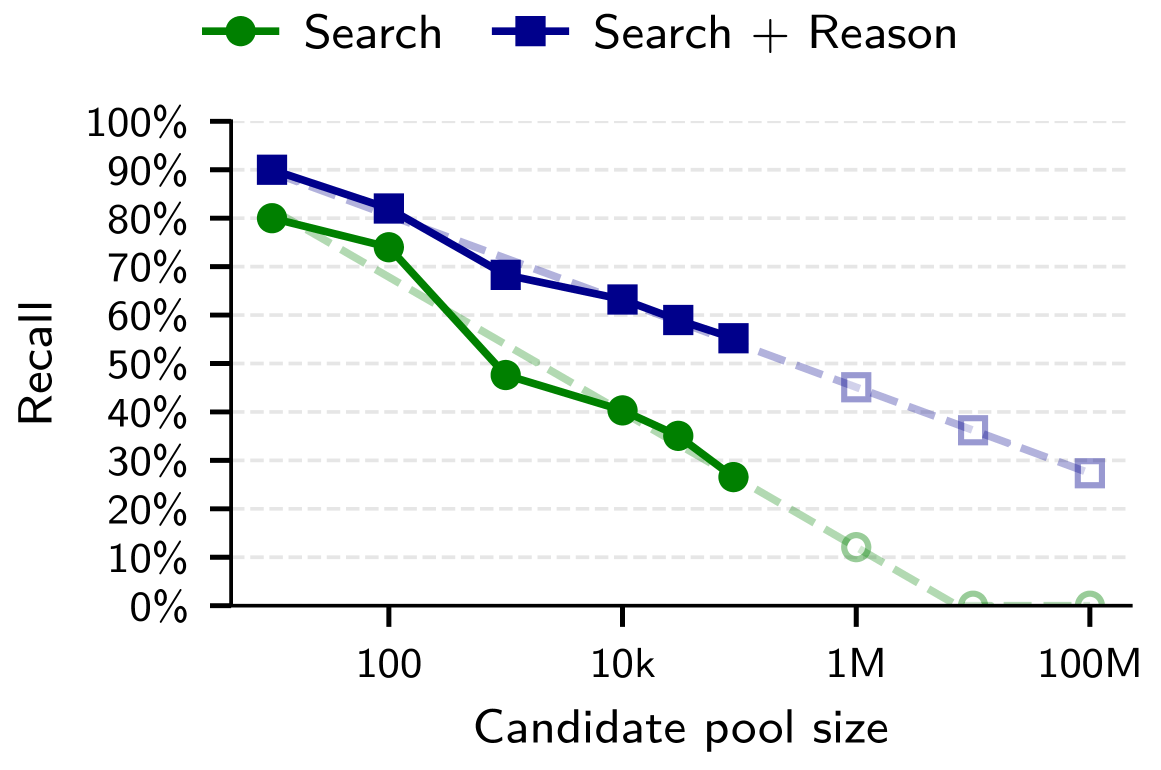
In the third scenario, the researchers split individual Reddit users’ comment histories into two halves, one year apart, and tried to match the halves to each other. About two-thirds of users were correctly matched, compared to less than one percent with the traditional approach.
When the language model got more compute time to reason, hit rates climbed further. Even with one million candidates, the attack could still succeed in roughly 35 to 45 percent of cases depending on the scenario, according to the researchers’ extrapolation.
Effective countermeasures are hard to find
The researchers paint a grim picture of the consequences. State actors could unmask pseudonymous accounts of dissidents or journalists. Companies could link anonymous forum posts to customer profiles. Criminals could launch tailored fraud campaigns at scale.
Against that backdrop, it becomes clearer why Anthropic is pushing back so hard against AI-powered mass surveillance in its dispute with the Pentagon.
Possible countermeasures like restricting access to user data or detecting automated scraping could make attacks harder. But the researchers are pessimistic: their pipeline is just a sequence of seemingly harmless steps like summarizing, searching, and sorting that are nearly impossible to tell apart from legitimate use.
In a test using data from a Steam profile, GPT-5 Pro refused to search, citing impermissible de-anonymization. Anthropic’s Claude also rejected the request. Deepseek and Manus.ai, on the other hand, were willing to search but didn’t turn up any useful results.


“Users who post under persistent usernames should assume that adversaries can link their accounts to real identities or to each other, and that the probability rises with each piece of micro-data they post,” the researchers write.
The study was approved by the ETH Zurich ethics committee. The researchers are not releasing their attack code or processed datasets, and they are not disclosing any identities.
AI News Without the Hype – Curated by Humans
As a THE DECODER subscriber, you get ad-free reading, our weekly AI newsletter, the exclusive “AI Radar” Frontier Report 6× per year, access to comments, and our complete archive.