
Abstract
Cyber Threat Intelligence (CTI) serves as a crucial indicator of cybersecurity events, providing critical evidence for analyzing cyberattacks and vulnerabilities. While existing deep learning approaches have shown value in processing urgent CTI data, accurately extracting cybersecurity event types and their associated arguments remains challenging due to CTI’s inherent complexity and data scarcity. Moreover, the lack of a large-scale annotated corpus in the cybersecurity domain prevents direct application of large language models (LLMs) to surpass the current methods’ performance. To enhance CTI information extraction efficiency, we propose the Cyber Attack Feature Interaction Information Extraction (CAFIIE) method. Our investigation reveals prevalent latent deep features in CTI threat entity interactions. Consequently, we implement multi-layer shallow feature interactions to capture these latent characteristics of threat entities and their relations. The CAFIIE model is further fine-tuned through few-shot learning to improve CTI feature utilization efficiency, making it particularly suitable for data-limited cybersecurity scenarios. Through experiments on three public and one private datasets, the CAFIIE method demonstrates superior accuracy and F1-score performance compared to existing baseline methods.
Introduction
In recent years, the continuous emergence of cyberattacks has posed significant threats to the cybersecurity defenses of nations worldwide. Cyber threat intelligence (CTI), which includes attack processes and defensive techniques, serves as critical material for providing timely and comprehensive descriptions of attack incidents, offering essential support for understanding the details of attacks. With the successful application of knowledge graphs in various vertical domains, researchers have proposed extracting diverse event-related information from CTI texts to construct cybersecurity knowledge graphs, thereby facilitating the analysis of security incidents and the inference of potential threats and probable defense strategies. However, lengthy CTI reports often contain substantial irrelevant information alongside sparse, domain-specific attack-related terminology, making it challenging for general information extraction techniques to accurately retrieve details of attack events. Consequently, the accurate and efficient extraction of event information from CTI has become an urgent problem to address.
The challenge of this issue lies in the complexity and scarcity of CTI. First, regarding complexity, cybersecurity incidents involve various attacked device names, program identifiers (IDs), Internet Protocol (IP) addresses, thread IDs, and other technical entities. These complex named entities appear infrequently in text, making it difficult for neural networks to be effectively trained and to capture their corresponding semantic information. Regarding scarcity, since cyberattacks are sudden incidents arising from offensive-defensive confrontations, they occur at a relatively low frequency. Moreover, only a limited number of cybersecurity firms possess the capability to analyze them, and concerns over the social and reputational impact on affected parties further restrict the availability of high-quality CTI texts.
In existing research, Sayara1 released the CASIE dataset and employed BERT as the base model to analyze CTI texts, evaluating the performance for both event types and multiple attribute information. Additionally, DNRTI2 and CySecED3 proposed cybersecurity incident datasets, respectively, and tested the extraction performance of their traditional machine learning methods in experiments. Although their methodologies were relatively simple and achieved limited performance, their publicly available security incident datasets laid a critical foundation for subsequent research. APT-KGL4 leveraged heterogeneous provenance graphs and cyber threat intelligence to detect Advanced Persistent Threat (APT) group information. NER4CTI5 utilized a semantically enhanced network to extract threat entities from CTI. Yue6 applied generative adversarial networks to identify relationships among threat entities in CTI contexts. However, these methods tend to rely on overly restrictive filtering conditions to extract single or limited categories of information, thereby failing to capture comprehensive details of attack events. To address the two challenges in CTI, we propose the CAFIIE, a novel technique that efficiently extracts attack types and multiple attribute information of events. Figure 3 illustrates the network architecture of the proposed CAFIIE framework.
Specifically, to address the complexity of CTI, we first employ multiple embedding methods to encode and concatenate contextual words in CTI texts, based on an in-depth analysis of domain-specific vocabulary. After obtaining sparse features with significant representation disparities, we perform dense embedding operations to reduce the heterogeneity among different embedded features. Inspired by DeepFM7, which integrates multiple features and uncovers latent feature interactions, we design a parallel multi-feature interaction network that combines an FM (Factorization Machine) layer and a hidden layer to generate dense embedded representations. Subsequently, we utilize a BiLSTM-FC network enhanced with attention mechanisms to perform deep semantic analysis on high-dimensional CTI features. This architecture enriches input information, enabling the neural network to comprehend contextual semantics in CTI texts better and significantly improving the analysis of domain-specific terminology. Finally, a Conditional Random Field (CRF) layer is applied to classify event types or attribute value types in CTI.
To tackle the few-shot learning scenario in real-world security incidents, we fine-tune our CAFIIE framework using few-shot learning techniques. We simulate few-shot conditions in experiments to evaluate CAFIIE’s performance after few-shot adaptation. The results demonstrate that our proposed method outperforms existing approaches across evaluation metrics.
The main contributions of our work are as follows:
-
1.
We explore deep features using a feature interaction architecture and propose CAFIIE, a method for extracting CTI event types and event arguments. The attention mechanism is incorporated into the general BiLSTM-CRF semantic analysis method to enrich the semantic features.
-
2.
To solve problems and challenges of information extraction in CTIs, we use the deep FM network to alleviate the complexity of CTI. In addition, we fine-tuned our CAFIIE method through few-shot learning to adjust the actual few-shot scenario.
-
3.
In the experiment, we not only test the performance of the CAFIIE method with other baselines in three public and one private dataset, but also fine-tune it in few-shot scenarios. The experimental results showed that our method got better accuracy and F1 scores than other baselines.
Related work
General information extraction
Early deep neural networks8,9 played a significant role in information extraction tasks. With the rapid growth of internet data, pre-trained language models10,11,12,13 have emerged as the dominant architecture for information extraction research. However, these general-purpose techniques typically require massive amounts of generic training data, making them unsuitable for complex and specialized Cyber Threat Intelligence (CTI) datasets that are often scarce in samples. This limitation results in suboptimal performance for extracting threat intelligence information. While few-shot learning approaches14,15,16,17 have been proposed to address the few-shot issue of data scarcity, they still struggle to effectively analyze the complex and domain-specific nature of threat intelligence texts.
Information Extraction for CTI
Research on information extraction for threat intelligence18,19,20 initially relied on rule-based construction and pattern-matching detection21,22. These methods required manual rule engineering and were limited to known attack patterns, making them unsuitable for extracting information from newly emerging advanced threats. In recent years, generative approaches for threat information extraction ?,23 have been applied to assist analysts in CTI reporting and analysis. Additionally, techniques for detecting and predicting cyber threats and attacks24,25,26 have shown progress. However, these methods often rely on strict assumptions and constraints, limiting their practical applicability and extraction performance.
To address these challenges, we propose CAFIIE, which leverages shallow feature interaction to enhance neural networks’ understanding of domain-specific and complex CTI terminology. Furthermore, we fine-tune the CAFIIE model using few-shot learning techniques to improve extraction performance in low-resource scenarios while enhancing model robustness.
Question definition
Figure 1 shows the entity and relation annotation task in the context of CTI. Event extraction of cybersecurity can be categorized into the following subtasks:
Event Type Extraction As the core entities of an event, event types can be composed of multiple words, different from the trigger word defined by a single word.
Event Argument Extraction The event argument is the attribute value of the attacking entity, which can precisely describe the characteristics and other attributes of the attack.
Event Relation Judgment Event relationships are analogous to attribute names, which connect entities (event types) with attribute values (event arguments).
Event Attack-state Judgment Analyze the syntactic temporal information in the text of cyber-attack events to decide whether an attack has occurred. Attack status is divided into three categories: Actual (the event has happened), Other (a failed or future event), and Generic (an undetermined/non-specific event).

The illustration demonstrates the entity and relation annotation task in the context of CTI. Specifically, the phrase “ransomed 1 bitcoin for each infected computer� is annotated as the Attack. Ransom event type. Other phrases such as “The hacker�, “the intranet�, “SONY in Japan�, “stole the PII of employees�, and “Saturday� are also annotated with their corresponding event argument types (e.g., “Person�, “Device�, “GPE�, “Capabilities�, “Time�). Additionally, there are annotations for relations between event types and event arguments, such as “Attacker-Person�, “Victim-Arg�, “Place-Arg�, “Attack-Pattern-Arg�, and “Time-Arg�.
The theory of CAFIIE Method
Pretraining model for word embedding
Word embedding27 is to map words into vectors for computation and representation of word features. One-hot is an early word embedding method. Then, Tomas Mikolov et al. proposed the Word2Vec model28,29, efficiently learning the embedding representation of independent words in a training corpus. The advantage of the pretraining model is that it is publicly released and downloadable, allowing for the incorporation of large-scale parameters that can fully capture the semantic features of words and incorporate relational features between words into vectors. In our experiments, we utilized the Domain-Word2vec pre-trained model30 for cybersecurity event type and argument extraction, achieving better extraction accuracy than the CASIE method.
Feature interaction for data enhancement
Enhancing the feature mining process can improve extraction accuracy and provide accurate information on cybersecurity event types and arguments, which helps determine the relations between cyberattack events and assess the status of attacks. Inspired by feature interaction, our feature mining method is a type of data enhancement, and the implementation process is shown in Fig. 2.
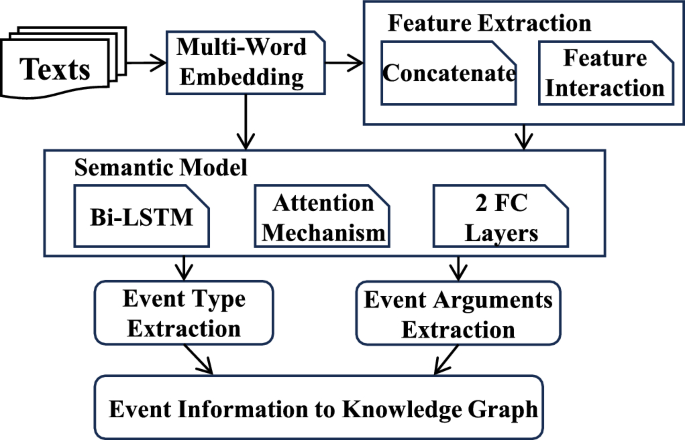
Experiment architecture.
Numerous studies have widely utilized feature interaction in the recommender systems domain, and we can classify these methods into three types, including Wide&Deep31, DeepFM7, and a series of PNN32 and PIN33. Formulation 1 is a mathematical function for linear regression. The independent input features (x_1, x_2, dots , x_n) are linearly combined to predict the output variable (y _ raw).
where n is the number of features in the sample, (x_i) is the value of the (i_th) feature, and (w_0) and (w_i) are the model parameters. Based on the equation 1, features are expanded to include a two-pair input FI by following equations:
FM34 provides a solution by decomposing the parameter (w_ij) into the product of two small matrices through the derivation of formulas. It adopts the matrix decomposition to approximate the cross-term parameter in Equation 3, as follows:
where k is the feature domains’ dimension, and (leftlangle v_i,v_j rightrangle) is the vector inner product:
A series of evolutionary FMs has been proposed to address the issue of insufficient sample size and inaccurate fitting of the (w_ij) parameter.
Field-aware Factorization Machines (FFM) FFM35 introduces the feature domain concept. The model selected a related vector from multiple hidden feature vectors for an inner product operation. It increases the representation of hidden vectors, distinguishes between features, and enhances the representation capability of features. The core equation of FFM is as follows:
Where i and j denote the (i_th) and (j_th) feature subscript, (f_i) and (f_j) represent the hidden feature variables, and the other variables have the same meanings as in the FM.
Attentional Factorization Machines (AFM) AFM36 leveraged an attention mechanism to distinguish the importance of different interaction features. The core equation of the AFM obtained based on the FM improvement is as follows:
Where (odot) is the element-wise inner product operation. The equation for computing the parameter (a_ij) based on the attention mechanism network is as follows:
(textbf W,b,h) is the parameter, and t represents the specification of the hidden layer of the attention network, denoted as the attention factor.
Other Complex Models Besides the mentioned above, high-order factorization machines (HOFM)37 is a generalization method based on second-order FM. FM with Follow the Regular Leader (FTRL-FM) is a study of applying Follow the Regular Leader (FTRL) optimization methods to FM models. In particular, FTRL has excellent sparsity and convergence characteristics.
Advantages of the Series of FM The FM series can efficiently train the weight parameters of the interaction features and generalize the parameters to unobserved interaction variables. Additionally, many optimization methods for FM calculate the parameters of the interaction terms. Therefore, they reduced training time complexity from quadratic to linear.
As for addressing the highly sparse features in CTIs, the advantage of the FMs focuses on three aspects: Firstly, the FM model enhances the representation of latent deep features by shallow feature interaction for independent and weakly correlated texts with discrete features. Besides, we can simplify the feature interaction process by matrix operations instead of recurrent structures. Meanwhile, increasing the order of interaction features can further improve feature representation and experimental performance.
The architecture of CAFIIE
For the cybersecurity event extraction, Fig. 3 shows the overall framework of our method, including the following aspects:
Multidimensional Embedding Input We utilized the top-performing word embedding methods from the CASIE, and we obtained the embedding of various preprocessed texts to enhance input features.
Feature Density To handle sparse features in the embedding layer, we used Dense Embedding to convert them into dense numerical forms. Subsequently, we leverage the DeepFM method to incorporate feature combination across frames. In the FM layer, all dense embedding vectors are computed using the inner product. The Hidden Layer employs a multi-layer neural network with standard dropout, using Sigmoid activation to prevent overfitting. Additionally, a shared nonlinear layer, located after the FM and Hidden Layer, generates results for multiple ReLU functions to obtain dense features.
Information Extraction Based on BiLSTM-ANN-CRF BiLSTM38 can extract rich semantic information from the text. The attention mechanism10 and the fully connected (FC) layer with dropout enhance the model’s information extraction ability and prevent overfitting during training, thereby improving its ability to recognize cybersecurity events. The conditional random field (CRF) determines and labels text words to obtain event types and arguments.
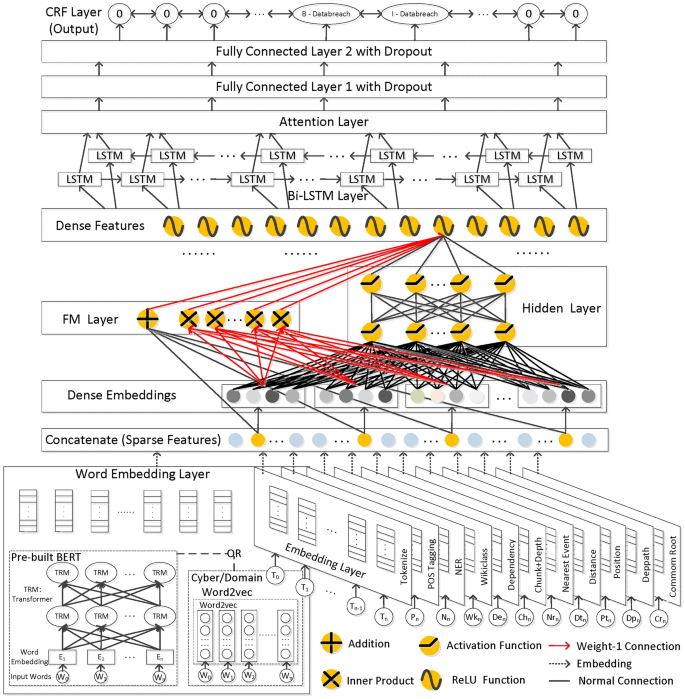
The Network Architecture of CAFIIE (The word embedding layer concatenates BERT or Word2Vec embedding for the original text and multidimensional embeddings of words from multiple semantic parsing stages together).
Model optimization analysis
Optimizing the computational efficiency of high-order interactive features is a critical aspect of feature engineering. Two primary strategies are post-construction feature selection and expert-designed complex features, which balance and manage computational expenses. Therefore, maintaining a reasonable balance in the number of complex features is crucial for improving model performance and reducing training time.
Explanation for the mechanism of feature interaction
The role of the interaction network is to perform correlation analysis on probabilistically related event attributes, uncovering latent semantic features to enhance the network’s textual understanding. However, due to the inherent nature of neural network training, we can only observe experiments on how the proposed feature interaction network improves attribute value extraction compared to conventional neural networks. To illustrate the functional mechanism of feature interaction as clearly as possible, we draw analogies to human-interpretable shallow feature interactions and provide examples of latent feature discovery, as illustrated in Table 1.
Experiments
In this section, we evaluate the event extraction performance of the proposed CAFIIE method against baseline methods on CTI texts, conducting comprehensive tests on both event type extraction accuracy and multiple event attribute extractions using F1 scores.
Experiment setup
Datasets
Table 2 presents the public and private datasets used in our experiments.
CASIE 1 Cybersecurity professionals meticulously selected 1000 articles from 5000 cyber news to build the CASIE dataset. This dataset encompasses five event types and over 20 types of event arguments.
DNRTI 2 It is a cybersecurity dataset for recognizing named entities with more than 6500 annotated sentences and 36400 annotated entities. Entities are categorized into 13 types, including Hacker Organization (HackOrg), Attack (OffAct), Sample File (SamFile), etc.
MalwareTextDB 39 It is a malicious code library comprising 6819 tagged sentences and 10983 tagged entities from 39 APT reports. Token annotations are categorized into Action, Entity, and Modifier.
Private Dataset Selected 1000 cyber threat event news from the open source CTI website40 in 2023, established a private CTI dataset with 7346 named entities. Following CASIE’s items, we categorized attack events and threat entities into five types and 23 types. Table 3 presents the distribution of specific entity types in the CASIE and private datasets.
Evaluation metrics
We adopted commonly used evaluation metrics, including precision (P), recall (R), F1 score (F1), and accuracy (Accu), in comparing experiments. The formulas for these metrics are provided below.
Where the subscripts TP, FP, TN, and FN are the components of the confusion matrix, N denotes the number of variables in each subscript category.
Comparison models
We compared the proposed algorithm with eight high-performing information extraction algorithms in terms of precision and recall. Specific algorithms include CRF41, Naivebayes-CRF42, BiLSTM-CRF43, IDCNN-CRF44, CNN-BiLSTM-CRF2, LSTM-BiLSTM-CRF2, Base (multi-embedding), Base-BERT1, BERT-HSA5, BERT-SSA5, Base-FI-BiLSTM-ANN-CRF(ours).We uniformly incorporated CRF as the final network layer added to all algorithms for a fair comparison and better performance.
Hyperparameter configuration of CAFIIE
The configuration of CAFIIE’s network layers (Domain-Word2Vec/BERT Embedding, Dense Features, BiLSTM, Attention, double FC, CRF). To maintain a fair comparison for experimental records, we retain the initial word embedding dimension at 100, which is the same setting as the CASIE experiment. After extensive experiments and debugging, we identified the optimal parameter setting. Table 4 shows the CAFIIE’s overall hyperparameter configuration.
Experimental results
Event type detection
Utilizing CTI event-type annotations in the CASIE dataset, this section compares the detection performance of our proposed CAFIIE method with the CASIE detection process. Table 5 is the experimental record of the CAFIIE algorithm, in which the detection rate of the “I-Phishing� event type is the highest, reaching 87%. It is 2% higher than the highest detection rate (85%) recorded in the CASIE1.
Notably, the “PatchVulnerability� event type usually consists of a single word, and the only “B-PatchVulnerability� label represents this whole type. There is no “I-PatchVulnerability� word, so we used the symbol “-� to refer to the empty data of “I-PatchVulnerability� in Table 5. Therefore, this experiment confirms the performance improvement effect of the proposed CAFIIE method on the cybersecurity event type detection on the CASIE dataset.
Event argument detection
Following the comparative methods in CASIE, we conducted event argument extraction experiments on three publicly available datasets and one private dataset. Table 6 summarizes our method’s accuracy in extracting the top entity types for each dataset, listing the top five entities by accuracy.
Since MalwareTextDB comprises only three entity types, Table 6 presents results for these types. Compared to the listed baselines, our method exhibits enhanced accuracy in extracting the main entity types on the three public datasets (CASIE, DNRTI, and MalwareTextDB). Table 7 shows the experimental results of our CAFIIE method and other baseline methods. The best performance metric for each dataset is in bold, and the suboptimal performance is underlined.
1. Our method is implemented in three different ways: Base+FI+BiLSTM+ANN+CRF, Base+BERT+FI+BiLSTM+ANN+CRF, and BERT+FI+BiLSTM+ANN+CRF. The experimental results showed that our method performed with higher extraction accuracy on four datasets. Among the three other networks of our CAFIIE, the Base+BERT+FI+BiLSTM+ANN+CRF model achieved the best precision on four datasets, and its performance in recall and FI score metrics outperformed most methods.
2. The differences in experimental indicators of the three proposed models reflect the necessity of comparing models. According to the results, the text information obtained through the context-independent multi-dimensional embedding method can achieve higher experimental performance after subsequent complex model processing. It showed the effectiveness of our innovative interactive feature mining in network structure.
3. Only our method achieves over 66% precision on the private dataset. It was demonstrated that our method affects the information extraction of CTIs.
Although the proposed method performs optimally in most situations, it only performs a slight advantage in the public datasets. The reason is that the proposed method is more suitable for complex CTI in the cybersecurity domain. We aim to create a professional cybersecurity knowledge graph from our dataset. More detailed and comprehensive cybersecurity vocabulary categories were defined during the text labeling process, enhancing the professionalism of the labeled data. It requires more professional knowledge and features. Therefore, on the private dataset, other methods generally perform well, and our method introduces interactive feature mining as added knowledge features to make the algorithm more suitable for professional fields and perform better.
To visualize the variation of accuracy during the training process across iteration epochs, we selected three new baseline methods for comparative analysis with the proposed approach, as detailed in the Fig. 4.
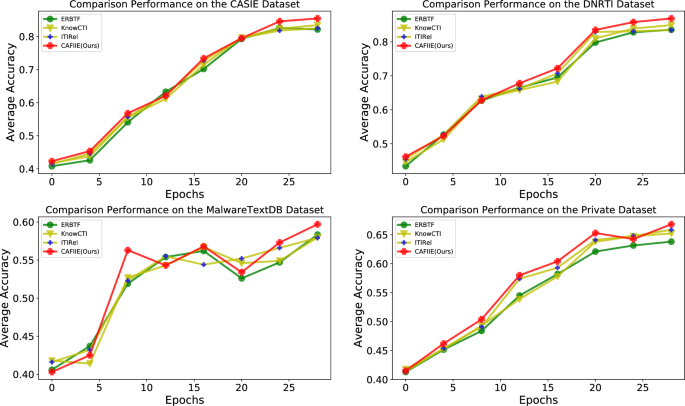
The comparison performance of four methods on different datasets.
The few-shot scenario in cybersecurity
Researchers designed few-shot learning for few-shot scenarios with limited categories in classification tasks. Due to sample constraints, features are sparse. Consequently, we chose CASIE and private datasets as the foundational datasets. In the cybersecurity domain, we categorized few-shot scenarios into three classes (3-way): communication data distorting attacks, data communication service disrupting attacks, and asset data destruction attacks. Due to the sparse features of CTI, the extraction efficiency in one-shot learning is poor. Hence, we simulated two groups of few-shot learning scenarios with five samples and ten samples (5-shot, 10-shot), omitting a single sample (1-shot) as the support set. Our experimental algorithms encompass the proposed CAFIIE model and the comparative model CASIE. Table 8 displays our experiments on CASIE and private datasets, affirming the efficacy of our FI-based algorithm for extracting CTI in few-shot scenarios.
Ablation study
To comprehensively evaluate the influence of different components on the CAFIIE method, ablation studies have been conducted. We focus on evaluating the impact of the FI, BiLSTM, and ANN on the performance of the CAFIIE. The results are presented in Table 9.
Compared to the complete CAFIIE network, we observed that the experimental group lacking FI exhibited the poorest performance across different datasets, followed by the group without BiLSTM. In contrast, the group without ANN demonstrated the best performance. This confirms the critical role of FI in the entire CAFIIE network, as it facilitates deeper contextual understanding for both the BiLSTM and ANN networks.
Discussion
Our proposed CAFIIE framework addresses two critical challenges in CTI extraction, including semantic complexity through hierarchical feature interaction and data scarcity via few-shot adaptation. The key findings are demonstrated in two items. Firstly, regarding accuracy improvement, the CAFIIE achieves a highest accuracy of 86.87% in the DNRTI dataset (Table 7), outperforming baseline models (Base+BERT+SSA: 86.32%) by 0.55%. This gain primarily stems from the shallow interaction module’s ability to resolve ambiguous entities and relations, reducing error propagation in downstream tasks. Secondly, regarding few-shot robustness, with five and ten annotated samples per event type, CAFIIE achieves better precision compared to the CASIE method (Table 8), validating its suitability for low-resource scenarios.
However, the current single-task training paradigm imposes substantial computational and temporal costs. Recent developments in continual learning demonstrate promising results for multi-task scenarios. Consequently, a key research direction involves investigating large-scale parameterized models that can simultaneously process multiple security event attribute extraction tasks without compromising accuracy.
Conclusion
This paper tackles the critical challenge of inefficient event information extraction in CTI analysis by introducing the CAFIIE framework. Our novel approach integrates shallow feature interaction with advanced attention mechanisms to effectively capture deep semantics in CTI texts, thereby achieving precise classification of both predefined event types and their associated attributes. To address the persistent issue of data scarcity in specialized domains, we incorporate few-shot learning techniques for robust model adaptation, with comprehensive experimental results demonstrating the framework’s superior performance. In the future, we plan to explore the integration of larger pre-trained language models and investigate continual learning paradigms to enhance the framework’s scalability for complex multi-attribute extraction tasks.
Data availability
The public CASIE, DNRTI, and MalwareTextDB datasets used in the comparison experiments are available in these repositories: https://github.com/Ebiquity/CASIE, https://github.com/SCreaMxp/DNRTI-A-Large-scale-Dataset-for-Named-Entity-Recognition-in-Threat-Intelligence, https://github.com/juand-r/entity-recognition-datasets/tree/master/data/MalwareTextDB. The related CASIE code used in this work is available on the release version: https://github.com/Ebiquity/CASIE.
Code availability
The related CASIE code used in this work is available on the release version: https://github.com/Ebiquity/CASIE. The code is freely accessible and can be used under the terms of the MIT License.
References
-
Satyapanich, T., Ferraro, F. & Finin, T. Casie: Extracting cybersecurity event information from text. In Proceedings of the AAAI conference on artificial intelligence 34, 8749–8757 (2020).
-
Wang, X. et al. Dnrti: A large-scale dataset for named entity recognition in threat intelligence. In 2020 IEEE 19th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), 1842–1848 (IEEE, 2020).
-
Trong, H. M. D., Le, D.-T., Veyseh, A. P. B., Nguyen, T. & Nguyen, T. H. Introducing a new dataset for event detection in cybersecurity texts. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 5381–5390 (2020).
-
Chen, T. et al. Apt-kgl: An intelligent apt detection system based on threat knowledge and heterogeneous provenance graph learning. IEEE Transactions on Dependable and Secure Computing (2022).
-
Liu, P. et al. Multi-features based semantic augmentation networks for named entity recognition in threat intelligence. In 2022 26th International Conference on Pattern Recognition (ICPR), 1557–1563 (IEEE, 2022).
-
Han, Y. et al. At4ctire: Adversarial training for cyber threat intelligence relation extraction. Electronics 14, 324 (2025).
-
Guo, H., Tang, R., Ye, Y., Li, Z. & He, X. Deepfm: a factorization-machine based neural network for ctr prediction. arXiv preprint arXiv:1703.04247 (2017).
-
Bengio, Y., Ducharme, R. & Vincent, P. A neural probabilistic language model. In Leen, T., Dietterich, T. & Tresp, V. (eds.) Advances in Neural Information Processing Systems, vol. 13 (MIT Press, 2000).
-
Collobert, R. et al. Natural language processing (almost) from scratch. Journal of machine learning research 12, 2493–2537 (2011).
-
Vaswani, A. et al. Attention is all you need. Advances in neural information processing systems 30 (2017).
-
Touvron, H. et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023).
-
Touvron, H. et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023).
-
Ding, N. et al. Parameter-efficient fine-tuning of large-scale pre-trained language models. Nature Machine Intelligence 5, 220–235 (2023).
-
Ashok, D. & Lipton, Z. C. Promptner: Prompting for named entity recognition. arXiv preprint arXiv:2305.15444 (2023).
-
Ziyadi, M., Sun, Y., Goswami, A., Huang, J. & Chen, W. Example-based named entity recognition. arXiv preprint arXiv:2008.10570 (2020).
-
Sun, W. et al. Metamodulation: Learning variational feature hierarchies for few-shot learning with fewer tasks. In International Conference on Machine Learning, 32847–32858 (PMLR, 2023).
-
Zhang, H. & Zhuang, Y. A unified label-aware contrastive learning framework for few-shot named entity recognition. arXiv preprint arXiv:2404.17178 (2024).
-
Zhao, X., Jiang, R., Han, Y., Li, A. & Peng, Z. A survey on cybersecurity knowledge graph construction. Computers & Security 103524 (2023).
-
Arazzi, M. et al. Nlp-based techniques for cyber threat intelligence. arXiv preprint arXiv:2311.08807 (2023).
-
Guo, Y. et al. A framework for threat intelligence extraction and fusion. Computers & Security 132, 103371 (2023).
-
Barnum, S. Standardizing cyber threat intelligence information with the structured threat information expression (stix). Mitre Corporation 11, 1–22 (2012).
-
Liao, X. et al. Acing the ioc game: Toward automatic discovery and analysis of open-source cyber threat intelligence. In Proceedings of the 2016 ACM SIGSAC conference on computer and communications security, 755–766 (2016).
-
Chiba, D. et al. Domainchroma: Building actionable threat intelligence from malicious domain names. Computers & Security 77, 138–161 (2018).
-
Sentuna, A., Alsadoon, A., Prasad, P., Saadeh, M. & Alsadoon, O. H. A novel enhanced naïve bayes posterior probability (enbpp) using machine learning: Cyber threat analysis. Neural Processing Letters 53, 177–209 (2021).
-
Bromander, S. et al. Investigating sharing of cyber threat intelligence and proposing a new data model for enabling automation in knowledge representation and exchange. Digital Threats: Research and Practice (DTRAP) 3, 1–22 (2021).
-
Zhao, X. et al. Target relational attention-oriented knowledge graph reasoning. Neurocomputing 461, 577–586 (2021).
-
Hinton, G. E. et al. Learning distributed representations of concepts. In Proceedings of the eighth annual conference of the cognitive science society, vol. 1, 12 (Amherst, MA, 1986).
-
Mikolov, T., Chen, K., Corrado, G. & Dean, J. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781 (2013).
-
Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S. & Dean, J. Distributed representations of words and phrases and their compositionality. Advances in neural information processing systems 26 (2013).
-
Padia, A. et al. Umbc at semeval-2018 task 8: Understanding text about malware. UMBC Computer Science and Electrical Engineering Department (2018).
-
Cheng, H.-T. et al. Wide & deep learning for recommender systems. In Proceedings of the 1st workshop on deep learning for recommender systems, 7–10 (2016).
-
Qu, Y. et al. Product-based neural networks for user response prediction. In 2016 IEEE 16th international conference on data mining (ICDM), 1149–1154 (IEEE, 2016).
-
Qu, Y. et al. Product-based neural networks for user response prediction over multi-field categorical data. ACM Transactions on Information Systems (TOIS) 37, 1–35 (2018).
-
Rendle, S. Factorization machines. In 2010 IEEE International conference on data mining, 995–1000 (IEEE, 2010).
-
Juan, Y., Zhuang, Y., Chin, W.-S. & Lin, C.-J. Field-aware factorization machines for ctr prediction. In Proceedings of the 10th ACM conference on recommender systems, 43–50 (2016).
-
Xiao, J. et al. Attentional factorization machines: Learning the weight of feature interactions via attention networks. arXiv preprint arXiv:1708.04617 (2017).
-
Blondel, M., Fujino, A., Ueda, N. & Ishihata, M. Higher-order factorization machines. Advances in Neural Information Processing Systems 29 (2016).
-
Zhou, P. et al. Attention-based bidirectional long short-term memory networks for relation classification. In Proceedings of the 54th annual meeting of the association for computational linguistics (volume 2: Short papers), 207–212 (2016).
-
Lim, S. K., Muis, A. O., Lu, W. & Ong, C. H. Malwaretextdb: A database for annotated malware articles. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 1557–1567 (2017).
-
Hackwebsite. hacknews. https://www.hackread.com/.
-
Lafferty, J., McCallum, A., Pereira, F. et al. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Icml, vol. 1, 3 (Williamstown, MA, 2001).
-
Yang, F.-J. An implementation of naive bayes classifier. In 2018 International conference on computational science and computational intelligence (CSCI), 301–306 (IEEE, 2018).
-
Huang, Z., Xu, W. & Yu, K. Bidirectional lstm-crf models for sequence tagging. arxiv 2015. arXiv preprint arXiv:1508.01991 (2015).
-
Yu, F. & Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv preprint arXiv:1511.07122 (2015).
-
Ma, X. & Hovy, E. End-to-end sequence labeling via bi-directional lstm-cnns-crf. arXiv preprint arXiv:1603.01354 (2016).
-
Wang, X., Liu, Z. & Liu, J. Joint relational triple extraction with enhanced representation and binary tagging framework in cybersecurity. Computers & Security 144, 104001 (2024).
-
Wang, G. et al. Knowcti: Knowledge-based cyber threat intelligence entity and relation extraction. Computers & Security 141, 103824 (2024).
-
Zhu, F., Cheng, Z., Li, P. & Xu, H. Itirel: Joint entity and relation extraction for internet of things threat intelligence. IEEE Internet of Things Journal 11, 20867–20878 (2024).
Acknowledgements
This work was supported by the National Key Research and Development Program of China (No. 2022YFB3104103) and the Major Key Project of PCL (Grant No. PCL2024A05-3).
Author information
Authors and Affiliations
Contributions
Yue Han created the model and wrote the manuscript. Weihong Han provided guidance and revision suggestions for manuscript writing. Aiping Li programmed the key project and guided manuscript writing. Shudong Li reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article
Cite this article
Han, Y., Han, W., Li, A. et al. Cyberattack event and arguments extraction based on feature interaction and few-shot learning.
Sci Rep 15, 31808 (2025). https://doi.org/10.1038/s41598-025-15138-x
-
Received: 06 December 2024
-
Accepted: 06 August 2025
-
Published: 29 August 2025
-
DOI: https://doi.org/10.1038/s41598-025-15138-x
Keywords